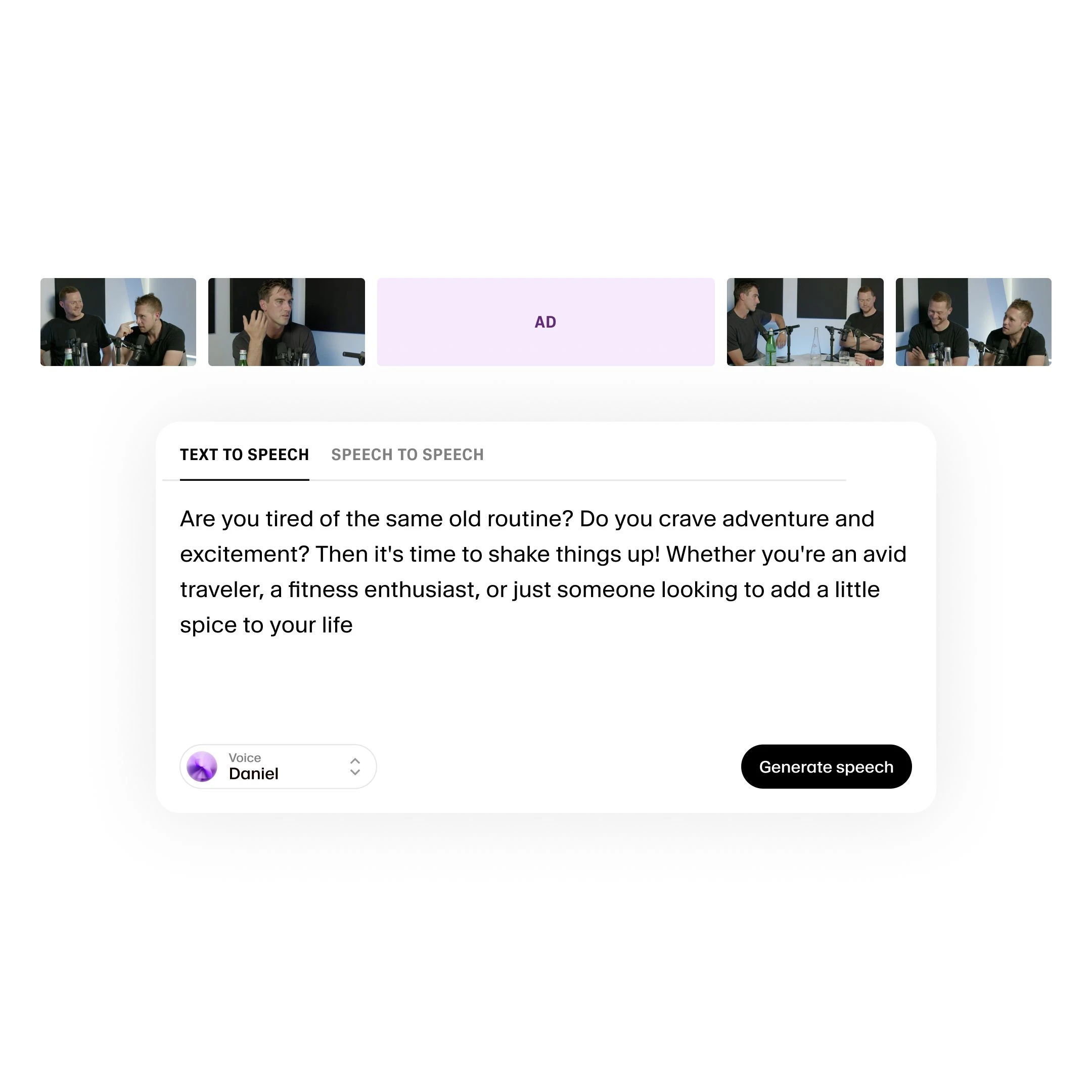
In an era where artificial intelligence is transforming daily life, the demand for the most realistic voice generator has significantly increased. These voice synthesis systems are developing at an exponential rate, resulting in lifelike vocal performances that convey emotions, sentiments, and individuality similar to human speakers. This technological evolution illustrates humanity’s enduring desire to replicate the subtleties of our own communication abilities.
Advancements in text-to-speech (TTS) technology have ushered in a new frontier where robots can engage listeners with voices that resonate on emotional and intellectual levels, blurring the lines between artificial and genuine speech. This article explores the intricacies driving this fascinating domain from historical developments to contemporary applications, while also addressing challenges and ethical considerations related to creating ultra-realistic voice generators.
> Experience the most realistic voice generator – try MicMonster for free today
The Evolution of Voice Generation: From Robotic to Realistic

The development of voice generation technology has spanned several decades, evolving from basic mechanical sounds to sophisticated neural networks capable of expressing human-like nuances. This progression illustrates not only technological growth but also cultural advancements in how we communicate and comprehend interactions.
Early Technologies and Their Limitations
Initially, text-to-speech systems relied primarily on rule-based algorithms governed by rigid linguistic frameworks. Phonemes were generated through predetermined rules rather than real human data, producing monotonous audio outputs that lacked the warmth of human speech. Users often found early TTS systems inherently clumsy and robotic, producing prototypes that never truly rested comfortably on the ears of listeners.
As users became frustrated with these flaws, researchers started exploring alternative methods. Concatenative synthesis emerged as a partial solution, utilizing pre-recorded segments of human speech to piece together entire sentences. Although a step forward, this approach still encountered significant hurdles regarding vocabulary constraints; unrecognized words or unusual sentence structures yielded inadequacies. It was clear that TTS required a rethinking and reevaluation.
> Turn your text into lifelike audio with the most realistic voice generator from MicMonster
Emergence of Parametric and Neural Approaches
With the arrival of parametric models, TTS technology made considerable strides. By analyzing various speech parameters such as pitch, duration, and volume, these systems generated phonetic sequences representing spoken language. While advances in formant synthesis provided enhanced expressive qualities, they remained computationally demanding and captured fewer nuances than desired.
However, the dawn of neural networks marked a watershed moment for voice generation. Deep learning techniques enabled increasingly intricate architectures that could encapsulate relations between text and sound in unprecedented ways. The use of recurrent neural networks (RNNs), and particularly Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs), elevated synthesized speech to previously unimaginable levels of expressiveness and reliability.
Natural conversation flowed seamlessly from these neural TTS systems, amplifying emotional undercurrents through prosody adjustments and intonation shifts—an intersection of linguistics, psychology, and engineering.
> Looking for the most realistic voice generator? Click here to start with MicMonster for free
Key Technologies Driving Realistic Voice Synthesis

At the heart of the most realistic voice generator technology are various innovative algorithms and methodologies designed to reproduce the intricacies of human voice with unparalleled accuracy. As the field rapidly evolves, myriad approaches are being explored, leading to groundbreaking applications in numerous sectors.
Understanding WaveNet Technology
Google’s WaveNet represents a pioneering achievement in realistic voice synthesis. A generative model built upon convolutional neural networks (CNNs), it operates by authenticating the raw audio waveforms employed in speech synthesis. By treating sounds as a sequence of discrete audio samples, WaveNet provides fine-tuned control over the resultant audio quality, requiring fewer audio samples to create more accurate representations of natural speech.
This revolutionary model factors in the physical properties of the voice, which leads to the emergence of vocal characteristics that include timbre, pitch, and cadence. Additionally, WaveNet generates subtle variations in pronunciation, ensuring every word dances with unique identity instead of sounding like a monotonous machine output.
> Say goodbye to robotic voices – discover MicMonster, the most realistic voice generator
Harnessing Sequence-to-Sequence Architectures
Developed alongside WaveNet, Google’s Tacotron has emerged as another salient player in the quest for the most realistic voice generator. By employing a sequence-to-sequence architecture, Tacotron takes input text and produces a spectrogram—essentially a visual representation of the frequency spectrum of the sound wave.
Afterward, the spectrogram undergoes conversion into audio through a vocoder system akin to WaveNet, culminating in the delivery of intelligible speech with impressive clarity. The interplay between text processing and spectrogram generation equips Tacotron to replicate the rhythms and tones central to human conversation.
Advances Through FastSpeech and Neural Vocoders
FastSpeech builds upon the foundations laid by both WaveNet and Tacotron while focusing on efficiency without compromising quality. Its design revolves around directly predicting mel-spectrograms from raw text, enhancing speed and making it ideal for real-time voice generation scenarios.
Complementing these synthesizing frameworks are neural vocoders, which refine and execute the transformations from spectrograms into beautiful auditory outputs. Models such as WaveGlow and Griffin-Lim play foundational roles, applying excellent audio manipulation techniques to render ultimate realism.
> Create professional-quality voiceovers with MicMonster, the most realistic voice generator available
Applications of Most Realistic Voice Generators

The impact of the most realistic voice generator transcends conventional boundaries—it reshapes industries and creates transformative experiences that enhance accessibility, engagement, and interaction in diverse environments.
Revolutionizing Accessibility Tools
One of the most impactful applications of realistic voice generators lies within accessibility and assistive technologies. Individuals facing difficulties due to visual impairments, speech impediments, or other limitations benefit tremendously from high-quality TTS systems. Notably, the profound improvements afforded by recent innovations elevate user experience, making interactions more relatable and less machine-like.
These human-like voices facilitate greater engagement; the empathetic tone emitted solves barriers faced by many users relying on such technologies to navigate everyday conversations. In environments spanning customer service chats to smart home devices, adopting the most realistic voice generator nurtures inclusivity, fostering better communication among individuals with varying abilities.
> Transform your projects with the most realistic voice generator – explore MicMonster now
Transforming Education Systems
The education sector also stands to gain significantly from the enhancements provided by the most realistic voice generator. Typically, educational frameworks require either attention-grabbing content delivery mechanisms or individualized assistance for learners with different needs. Text-to-speech engines generate engaging content, making learning resources consumable for individuals who struggle with reading comprehension or simply prefer auditory engagement.
Moreover, e-learning platforms harness realistic voice generators to provide insightful analytics tailored to students’ preferences. Custom voice prompts cultivate personalized learning experiences, facilitating interactions that feel far removed from traditional textbook encounters.
Enhancing Immersive Experiences in Entertainment
Within the ever-evolving world of entertainment and gaming, realistic voice generators open new frontiers of interactivity. High-fidelity TTS empowers characters with authenticity, creating dynamic narrative arcs where virtual actors react to player decisions with human-like emotional depth.
Additionally, this technology applies to audiobook narrations and media localization through realistic character dialogues, enhancing storytelling that transcends geographical borders. Capturing consumers’ imagination becomes increasingly feasible when characters resonate with their vulnerability and distinct narrative-driven experiences.
> Need the most realistic voice generator? Get started for free with MicMonster’s AI tool
Evaluating the Realism of AI-Generated Voices
Measuring the efficacy and realism of AI-generated voices requires a nuanced understanding that goes beyond what meets the ear. Researchers and technologists adopt various techniques and methodologies to determine areas of improvement and the ultimate capabilities of these advanced systems.
Subjective vs. Objective Assessments
An integral aspect of evaluating synthesized voices involves balancing subjective and objective assessments. Subjective evaluations typically rely on human judges who actively listen and critique generated speech across metrics like fluency, naturalness, clarity, and overall likeness to human voices.
In contrast, objective assessments employ methodologies analyzing specific acoustic features of generated speech using algorithms that gauge factors such as fundamental frequency, phoneme durations, and spectral characteristics. Combining these two approaches yields comprehensive insights regarding voice performance, highlighting strengths while illuminating areas warranting further refinement.
> Enhance your content with natural, lifelike audio from the most realistic voice generator
Real-World Use Cases
When assessing the realism of synthesized voices carefully, researchers engage real-world use cases to inform their findings. Application testing occurs within various environments outside of controlled laboratory settings, pinpointing individual experiences and soliciting feedback about synthesized interactions with technology.
User scenarios enable teams to pinpoint prevailing preferences, allowing for iterative development that responds to actual customer needs. Ultimately, this evolutionary cycle ensures adaptive responses to diverse audiences.
Cognitive Load Analysis
Evaluating cognitive load presents another dimension warranting careful consideration. Examining how users emotionally respond to TTS voices determines if the synthesized voice matches context and enhances communication effectiveness. Cognitive load analysis evaluates whether the generated speech aids understanding or detracts from interaction, ensuring that implementation does not become cumbersome for users.
> MicMonster delivers the most realistic voice generator – click here to try it for free
Ethical Considerations and Future Implications of Realistic Voice Synthesis
While advancements in voice technology afford unprecedented opportunities, they also yield numerous ethical complexities and potential implications. Understanding and addressing these issues is crucial to fostering the responsible development and application of the most realistic voice generator technology.
Risks of Misuse and Malicious Intent
One of the primary concerns surrounding realistic voice synthesis arises from the ease with which fraudulent manipulations can happen. Voice cloning systems capable of replicating individual vocal traits raise ethical quandaries. For instance, bad actors can employ such technologies for deceptive purposes, potentially undermining trust within personal, political, or commercial contexts.
As synthetic voices become indistinguishable from reality, establishing regulations, standards, and ethical guidelines becomes paramount. Developers must remain vigilant about safeguards that prevent misuse—clear ownership rights and consent mechanisms coupled with regulatory frameworks will help delineate acceptable practices within this landscape.
> Bring your ideas to life with the most realistic voice generator – start using MicMonster today
Social Responsibility and Accountability
Beyond the immediate concerns surrounding fraud lies a broader imperative to explore social responsibility and accountability associated with hyper-realistic voice technology. Enhanced TTS systems engender responsibilities among developers and organizations necessitating transparency and user-centricity throughout the voice synthesis journey.
For stakeholders to maintain ethics within their practices, industry-level discussions should foster environments fostering collaboration between designers, regulators, and end-users. Such dialogues remain critical to ensuring collective benefits extend equitably to society.
Long-term Implications for Communication Dynamics
With continuous advancements inevitably altering communication dynamics across generations, exploratory studies into long-term effects will shed light on potential ramifications. As reliance on voice synthesis grows, questions arise relating to interpersonal connections, emotional cognition, and the value of authentic interactions.
A deep appreciation for the subtleties inherent in human communication could become diluted if synthetic voices begin to dominate personal, professional, and creative spaces. Future research should prioritize examining how society adapts in response, informing strategy and intervention efforts aimed at cultivating meaningful relationships.
Read more:
- MicMonster Text to Speech: Transform Text into Natural-Sounding Voiceovers Effortlessly
- MicMonster AI Voiceovers Revolutionizing Audio Content Creation
- A Comprehensive Review of MicMonster Transforming Text into Natural-Sounding Speech
Choosing the Right Voice Generator for Your Needs
Selecting a fitting voice generator to suit unique requirements necessitates thorough consideration of various factors, including purpose, audience, and budget constraints. Individual applications dictate different priorities, underscoring the importance of evaluating available options with insight and discernment.
Identifying Core Use Cases and Objectives
First and foremost, understanding the core use case determines the most suitable voice generator for each scenario. Whether generating voices for accessibility, e-learning, entertainment, or marketing content matters profoundly impacts the selection process. Specific scenarios may call for emotional expression, clarity, speed of delivery, or compatibility with other applications.
Even within single domains, targeted objectives vary immensely. Developers crafting a dynamic gaming environment may seek expressive, character-driven voices, whereas those designing navigation aids for visually impaired users might prioritize clarity and consistency. Carefully delineating these distinctions informs the entire decision-making journey.
Assessing Technical Features and Compatibility
Once identified, the next stage involves scrutinizing the technical attributes and compatibility of the chosen synthesis systems. Prominent aspects encompass supported languages, dialects, voice customization options, and supported integrations with other tools or platforms.
Compatibility illustrates the degree to which the TTS technology meshes well within existing software ecosystems. Ensuring seamless connections permits smooth collaboration between functions, optimizing output while providing end-users a more cohesive experience.
Exploring Licensing Models and Pricing Structures
Ultimately, considering pricing and licensing structures serves to cement choices among prospective alternatives. Delve into various business models available—some solutions promise extensive packages; others may leverage pay-as-you-go schemes or subscription-based access.
Conducting comparisons that reflect on both initial investments and long-term commitments becomes essential for staying within target budgets while realizing intended goals—and striking an equilibrium between financial responsibility versus functional clarity results in well-informed decisions.
Conclusion
The quest for the most realistic voice generator remains a captivating journey shaped by relentless innovation and discovery within the fields of artificial intelligence and machine learning. As deep learning techniques draw closer to emulating human speech with uncanny verisimilitude, the future looks poised to unlock even greater possibilities.
From revolutionizing accessibility tools to enhancing interactive experiences across entertainment, education, and beyond, the power and potential of this technology remain immense. However, this advantage carries with it profound ethical considerations demanding attention—the responsibilities of stakeholders to pursue continuous dialogue, foresight, and mutual respect within this space will ultimately define the legacy of voice generation technology.
Furthermore, as society transitions deeper into this new age, melding the digital and organic facets of voice communication will inspire novel conversations about authenticity, identity, and connection—a trend characterized by fluidity rather than confinement. With progressive exploration, imagination, and ethical awareness, the aspirations embedded in the most realistic voice generator pave the path forward—even as the telling of our unique tales continues, championed by those curious enough to share them.
0 responses to “Most Realistic Voice Generator: Top Picks for Natural Text-to-Speech Solutions”