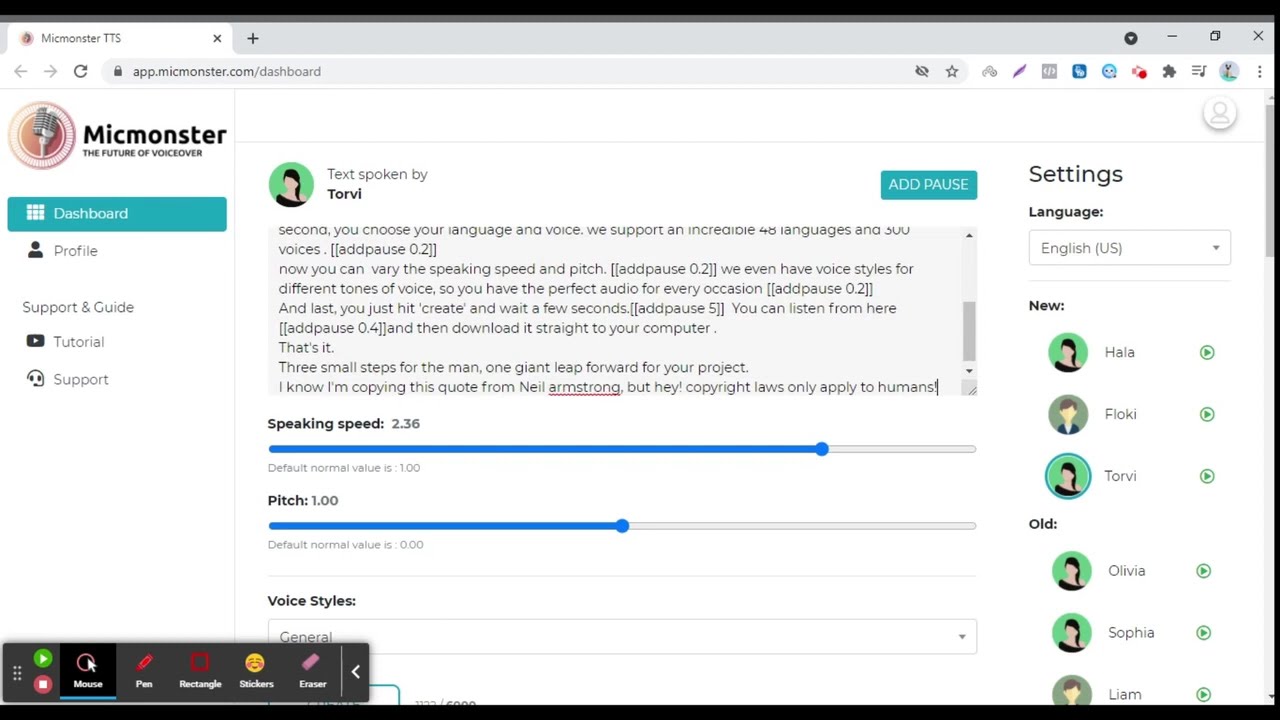
Natural sounding text to voice technology has evolved tremendously in recent decades, driven by advancements in machine learning and artificial intelligence. The desire to create lifelike simulations of human speech has led to innovations that blur the boundaries between how machines and humans communicate. As we navigate through this rich landscape, we’ll uncover the myriad dimensions of natural sounding text to voice, exploring its evolution from basic speech synthesis to today’s cutting-edge neural networks.
> Turn your text into natural sounding voice effortlessly with MicMonster’s free AI tool
The Rise of Natural-Sounding Text-to-Speech MicMonster

The pursuit of natural sounding text to voice has roots reaching far back into the mid-20th century. From those early days of rudimentary synthesizers producing only simple sounds, the journey has been anything but linear. Each decade witnessed a new wave of technological breakthroughs, challenges faced, and evolving methodologies aimed at breathing life into synthesized sounds. Today, we find ourselves grappling with the endearing achievements of past developments as well as modern ambitions for voice synthesis.
The Early Years of Speech Synthesis
In its initial stages, TTS systems were largely experimental, comprised of mechanical and electronic devices that utilized basic waveforms. These voices conformed to a strict monotone and often sounded robotic, leading to widespread skepticism surrounding their application. Researchers focused on concatenative synthesis, which involved piecing pre-recorded segments of human voice to construct cohesive outputs. While this technique allowed mere functionality, it brought forth uncanny resemblances that were jarring to listeners—artificial pauses and unnatural transitions marred the experience.
Revolution was slow, and the challenges faced by developers were enormous, as they grappled with how to simulate the intricate aspects of human speech. At times, these hurdles demotivated even the most driven innovators. Yet, it was during this formative phase that foundational concepts began to solidify, paving the way for advanced approaches that would radically alter the fabric of speech synthesis.
> Looking for a natural sounding text to voice solution? Try MicMonster for free today
Influential Technological Developments
As computing power surged, researchers took significant strides toward improving the quality and richness of synthetic voices. Innovations in formant synthesis brought about a realization that modeling the human vocal tract could yield better results. Ultimately, this paved the way for statistical parametric synthesis, where sophisticated algorithms learned from vast datasets of spoken language. These algorithms began recognizing the nuances associated with volition, pitch, inflection, and rhythm—the hallmarks of human conversation.
Breathlessly watching the burgeoning advances unfold, developers eagerly fine-tuned the parameters to reflect local dialects, varied accents, and vivid expressivity. Through painstaking efforts, the early TTS systems gradually morphed from sterile mechanical voices to more relatable speaking patterns. As they embarked upon the digital transformation, researchers uncovered possibilities previously deemed impossible.
From their nascent beginnings, natural sounding text to voice began inching toward creative expression; seamless integration into applications became tantalizingly within reach. But it would be the onset of the 21st century that bore witness to an unprecedented metamorphosis: the arrival of neural network-based languages, yielding a colossal leap forward in the provision of lifelike speech.
Neural Network Breakthroughs and Their Impact
With the birth of neural text-to-speech solutions, TTS reached all-new heights of fidelity. Harnessing the capabilities of deep learning, engineers deciphered linguistic data at levels unheard of prior. By forming complex relationships among words, tones, and emotional expressions embedded in human speech, AI-driven models now generated speech that not only articulated words accurately but also conveyed subtleties of meaning, emotion, and context.
As waves of excitement washed over diverse industries, businesses demonstrated their commitment to integrating AI and transforming customer experiences. Enterprises sought natural sounding text to voice to enhance personalized interactions, while educational institutions explored avenues to foster immersive learning using speech synthesis. The thirst for innovation and engagement reverberated like an echo across the globe.
Fast-forwarding to contemporary times, companies eager to capitalize on this growing technology rapidly embraced the age of neural networks. Utilizing extensive libraries filled with recordings spanning different demographics, researchers adeptly crafted voices with distinct tonal characters and styles. Users could choose from various personalities, allowing organizations and consumers alike to customize experiences that felt intimate, engaging, and alive.
> Experience lifelike audio with MicMonster, the best natural sounding text to voice generator
Key Technologies Driving Natural Text-to-Speech
The remarkable evolution of text-to-speech capabilities stems from advancements in several key technologies underlying the development of natural sounding text to voice. Each component plays an integral role and, when woven together, creates the sweet symphony of human-like articulation to resonate through the world.
Machine Learning and Deep Learning Techniques
Machine learning has revolutionized numerous fields by automating processes and enabling machines to learn from vast amounts of data. Within the realm of natural sounding text to voice, deep learning algorithms have emerged as pivotal force providers. Leveraging neural networks, these techniques delve into input data, building layers of abstraction to recognize and represent complex relationships in speech patterns.
Access to massive datasets has empowered developers to synthesize richer voices. The process of training these systems involves exposing them to hours of recorded audio from multiple speakers who display different emotional ranges and speaking styles. This variety enables the models to comprehend variations in cadence, word choice, and inflection crucial for generating expressions mirroring the intricacies of human conversation.
By delving deeper into data than ever before, developers unlock profound insights into tone—understanding not merely the phonetics but the very spirit imbued within spoken language. The generative capabilities of machine learning frameworks (particularly those employing recurrent neural networks) allow text to morph into seamless audio waves, creating vocal productions that resonate profoundly with audiences.
> Say goodbye to robotic voices – transform your text into natural sounding audio with MicMonster
Feature Extraction and Representation
A critical aspect contributing to the effectiveness of natural sounding text to voice systems resides in their ability to process and represent features inherent to speech. For instance, transforming raw audio signals into feature representations entails capturing qualities such as amplitude, pitch, loudness, and duration—all vital attributes that influence the perception of speech.
These extracted features provide essential information for the synthesis process, guiding the model to produce output that aligns with desired characteristics. Enhanced feature representation ensures a smoother transition between words and phrases; rather than awkward breaks or clipped sounds, the speakable content emanates fluidity and coherence.
Continual advancements in signal processing techniques have refined the efficiency and accuracy of feature extraction, revolutionizing how synthesized speech… …is produced. Researchers also explored multi-resolution analysis, temporal changes, and frequency bands to capture subtleties in speech better than earlier iterations were capable of accomplishing.
As the field progressed, machine learning practitioners began integrating new paradigms for representation that offered valuable insights from synchronized audio-text formats. These transformations allowed systems to better understand contextual dependencies, leading to more natural, conversational flows. Consequently, the paragraphs created by text-to-speech engines realized significant improvements in rhythm and tonality, mimicking real human conversation more closely.
> Create professional voiceovers with a natural sounding text to voice tool – start with MicMonster
Waveform Generation Techniques
The final stage in the production of natural sounding text to voice lies in waveform generation. The digital representation of sound requires advanced synthesis techniques that translate learned parameters into audible output. Traditionally, concatenative synthesis focused on stringing together pre-recorded units of audio, but this approach limited versatility and natural fluency.
Recent developments pivot towards neural vocoders, such as WaveNet or Tacotron-2, which employ deep learning-based algorithms to generate waveforms directly from feature representations. Instead of relying solely on existing audio snippets, these models synthesize sounds from scratch, enabling exquisite control over the generated characteristics. This fresh paradigm has empowered developers to create voices that convincingly replicate not only language fluency but also emotional expressiveness.
Through neural vocoders, researchers manipulate phonemes and semitones while adjusting prosody, pitch shifts, and articulatory parameters. This results in remarkably coherent outputs where nuances in stress, intonation, and emotion are easily conveyed to listeners. Thus, the lifelike complexity and rich texture of synthetic speech embolden developers to reach unprecedented heights, inviting users further into the realm of engaging auditory experiences.
> Discover the power of natural sounding text to voice conversion with MicMonster’s free AI generator
Get high-quality, natural sounding voiceovers instantly using MicMonster’s advanced text to voice tool
Need a natural sounding text to voice generator? Click here to explore MicMonster for free
Transform your projects with MicMonster, the ultimate natural sounding text to voice solution
Bring your words to life with natural sounding text to voice – try MicMonster now for free
Applications of Natural Text-to-Speech in Various Industries
The versatility of natural sounding text-to-voice technology finds applications across multiple sectors, reshaping how businesses interact with their clients while also fostering personalized engagement. Here, we explore several industries where TTS is transforming quotidian processes into dynamic interfaces that speak—figuratively and literally—their audiences’ languages.
> Discover the power of natural sounding text to voice conversion with MicMonster’s free AI generator
Education and Learning Environments
Within education, natural sounding text-to-speech serves as a transformative instrument, cultivating inclusivity among students while making learning more accessible. For individuals with visual impairments, dyslexia, and other learning disabilities, dynamic interaction through synthesized speech opens avenues that help mitigate barriers typically faced in traditional learning environments.
Text-to-speech applications can seamlessly narrate reading materials, turning textbooks and digital content into auditory resources. Personalized interactions enhance lesson engagement, encouraging learners to absorb information at their own pace without feeling strained or overwhelmed. Moreover, educational tools such as language-learning apps now harness this technology to provide realistic pronunciation examples, allowing users to practice speaking while receiving feedback on their performance.
As educators incorporate TTS into classrooms, they empower students to cultivate strong language skills and foster confidence in communicating effectively. Students engage actively, leading to improved retention and better outcomes in various subjects—all achievable through the guiding allure of natural-disounding voice synthesis.
> Get high-quality, natural sounding voiceovers instantly using MicMonster’s advanced text to voice tool
Customer Service and User Experience
Businesses nowadays recognize that personalized interactions serve as the heartbeat of customer satisfaction. Natural sounding text-to-speech enhances help desk systems, chatbots, and IVR solutions, ensuring seamless communication between humans and machines. By providing immediate, articulate responses, organizations elevate user experiences that make them feel valued and understood.
Moreover, companies tailor TTS responses to reflect brand voice while resonating with diverse demographics. Whether soothing tones for healthcare helplines, upbeat narration for entertainment platforms, or motivational encouragement in fitness applications, tailored experiences resonate with individual preferences. As a result, enhanced communication fosters loyalty and drives retention rates.
Additionally, automated phone systems employing natural sounding TTS reduce customers’ frustration in navigating menus while delivering swift reconnecting to support personnel. In a world characterized by relentless connectivity, the power of lifelike speech in customer service showcases the very essence of what it means to value every interaction.
Accessibility for Disabled Individuals
The impact of natural sounding text-to-speech transcends mere convenience; it’s a vital tool for increasing accessibility for disabled individuals. By converting written content into auditory formats, TTS democratizes information consumption and empowers individuals who might otherwise find it challenging to access printed materials.
Consider, for instance, mobile applications designed for visually impaired users. With the ability to read text aloud, navigate web content, or announce binary alerts, these applications promote independence and empowerment. TTS technologies allow everyone to participate in daily activities such as shopping, booking transportation, or engaging with digital platforms without dependence on others.
The growing societal commitment to inclusivity means innovation must evolve continually. As natural sounding text-to-speech capabilities expand alongside artificial intelligence refinement, both technology and society strive towards breaking down historical barriers faced by diverse populations, enhancing connectivity and realizing equal opportunities.
> Need a natural sounding text to voice generator? Click here to explore MicMonster for free
Content Creation and Media Production
In the rapidly evolving landscape of media production and content creation, natural sounding text-to-speech emerges as a powerful ally. Creators and marketers harness this technology to generate voiceovers that breathe life into explanatory videos, podcasts, and tutorials without necessitating extensive recording sessions.
By automating voice generation, creators gain the freedom to focus on crafting content while minimizing potential roadblocks associated with traditional voice talent acquisition. From animated characters speaking invocations to immersive storytelling, TTS nurtures creativity and accelerates production timelines.
Furthermore, brands increasingly embrace diverse voices by allowing audience members to select tonal styles that resonate with their preferences. This interactivity cultivates stronger connections between creators and their audiences, fostering a culture wherein clients feel valued and associated with their endeavors.
Evaluating the Quality and Naturalness of Text-to-Speech
As natural sounding text-to-speech gains momentum, assessing its quality and naturalness becomes paramount. The experience a listener derives hinges upon key factors influencing their perception. Continuous innovation prompts developers and researchers to formulate benchmarks that withstand rigorous scrutiny in the realm of speech synthesis.
> Transform your projects with MicMonster, the ultimate natural sounding text to voice solution
Perceptual Evaluation Metrics
The assessment of text-to-speech systems often incorporates perceptual evaluation methods, which emphasize human judgment in determining quality. Researchers engage listeners, presenting them with samples of synthesized speech to gather insights regarding specific qualities such as intelligibility, naturalness, and expressiveness. These metrics pave the way for comprehensive analyses that do not merely hail improvement based on technical parameters alone.
Listener studies offer useful datasets that enable developers to delineate weaknesses within current generative models. Recognition of deficits illuminates aspects requiring fine-tuning while emphasizing the nuance of human speech perception—an element frequently overlooked during rapid technological advancement. Ultimately, these iterative cycles of evaluation inform the emergence of natural-sounding output that engages users on an intimate subtextural level unique to human interaction.
Objective Measures of Speech Synthesis Quality
Complementing subjective assessments are objective measures used to gauge critical attributes governing text-to-speech output. Researchers have developed instrumental approaches that quantify phenomena, such as speech clarity, fidelity, and coherence.
Through spectral analysis, vocal tract characteristics are analyzed to deliberate on fundamental frequencies and harmonic features. Such information becomes invaluable as developers utilize it to delineate the difference between high-quality and mediocre synthesis. Novel signal-processing techniques work in symbiosis, yielding reliable insights that define optimal ranges of performance while maximizing interoperability across devices and platforms.
As systems progress toward sophistication, combating ambiguity inherent in traditional measures remains crucial. Incorporating effective evaluation frameworks ensures sustained improvement while paving the way toward understanding how to optimize user experience through continuous technological enhancements.
> Bring your words to life with natural sounding text to voice – try MicMonster now for free
Naturalness and Expressiveness
Above all, the ultimate indicator of success in natural sounding text-to-speech lies in evaluating how well a particular system channels the essence of human expression. Fascinating explorations into emotional speech synthesis spark interest within the community, prompting innovative responses capable of reflecting a myriad of feelings and variations in tone.
When synthesizing voices, it is essential to comprehend subtle emotions intertwined with spoken words; effective projects gracefully incorporate pauses, breath patterns, and shifting inflections that imbue text with vividness. Factors such as sarcasm, enthusiasm, excitement, and nurturing tones become paramount as artificial intelligence endeavors to interpret linguistic sentiment, drawing on profound data sets for finer articulation of meaning.
Listeners must feel that they connect emotionally to the voice emanating from speakers as they consume content. If successful, these systems captivate attention, unlocking transformative possibilities for narratives unimagined just decades ago.
Challenges and Future Directions in Natural Text-to-Speech
Despite remarkable advancements in text-to-speech technology, various challenges linger that require strategic navigation. Innovators face obstacles necessitating careful considerations, from addressing challenges concerning diversity to ethical implications surrounding use cases.
Diversity and Representation in Voice Synthesis
Developers routinely confront the challenge of ensuring adequate representation across segments of voice synthesis. Striving for diversity in accents, dialects, and mannerisms advances the industry; singular-focused deployments ultimately alienate specific communities, thereby contradicting the central ethos of global equity.
Manufacturers courageously venture into research dedicated to expanding voices available for synthesis. Curated voices reflect the spectrum of human identity, promoting resonance and cohesion across different ethinicities and cultures within synthesized outputs. Greater emphasis on constructing diverse datasets serves as a pathway to unite communities through collective engagement in conversations—conversations worthy of being shared and cherished.
Addressing Contextual Variability
Variability in context presents another formidable hurdle in natural sounding text-to-speech applications. Progressing toward seamless dialogue necessitates robust handling of situational context and nuanced meanings within conversations. Numerous factors—such as cultural differences, emotional states, and even milieu—bear crucial implications on interpreting speaker intent.
For instance, deploying TTS functionality in social media frameworks ushers captivating engagements while necessitating acute awareness of emojis, slang, and colloquial expressions. Skilled implementations work to ensure resonance, guiding user perspectives towards comprehending blended communicative cues. Harnessing natural language processing enables systems to hone entries specific to moments that contribute to building relational dynamics, shaping authentic, relatable interactions.
Ethical Implications Surrounding AI-Generated Speech
Investing wholeheartedly within the era of generative AI compels serious introspection concerning the ethical implications surrounding voice synthesis technology. Instances of misuse in creating misleading audio clips or replicating voices without consent propelled global conversations regarding authenticity and accountability surrounding synthetic creations.
Developers must establish ethical guidelines converged around transparency, informed consent, and assurances against potential exploitation. Regulatory frameworks focusing on respect for privacy and ownership become critical as pursuit towards personalization intensifies. Consciously managed discourse engenders trust within user communities and corporations involved in voice development, upholding values reflective of our interconnectedness.
The Road Ahead: Envisioning Tomorrow’s TTS Systems
Looking ahead, the contours of future natural-sounding text-to-speech promise to unveil continued metamorphosis. Developers will navigate the intricate complexities of human communication with gusto, prying open boxes once tethered shut amid theoretical constraints. Innovations incorporating advancements from speech recognition dynamically feed systems refined by real-time stimuli, reinforcing adaptive capability.
The melding of augmented and virtual reality with text-to-speech tantalizes prospects where sounds augment surroundings while instilling deeper engagement. Imagine gaming and training prowess intertwining, culminating in lifelike narrations responsive to players’ actions or decisions—a thrilling wordscape of possibilities awaits eager explorers.
Traditional linearity may yield further transformation by combining instruments aging along varying axes with temporal intelligence, paving fluid connections drawn across decades of struggles for refining artisanal output. As networks flourish through synergy and collaboration, people and systems jointly turn the page, creating conversational pathways unbound by technology’s previous limitations.
Read more:
- MicMonster Text to Speech: Transform Text into Natural-Sounding Voiceovers Effortlessly
- MicMonster AI Voiceovers Revolutionizing Audio Content Creation
- A Comprehensive Review of MicMonster Transforming Text into Natural-Sounding Speech
Ethical Considerations and Impact of Natural Text-to-Speech
The rise of natural sounding text-to-speech carries paramount ethical considerations becoming entwined with its foothold within diverse ecosystems. As technology progresses and permeates verticals, attentiveness to its influences cannot be understated—both positive and negative—in shaping societal values, mindsets, and perceptions.
Ownership and Consent in Voice Replication
One significant ethical dilemma revolves around the issues of ownership and consent when utilizing synthesized voices. Historical precedents demonstrate instances where voice replication technology inadvertently invokes debates concerning individual rights. Developers must be acutely aware that permissions to use recorded likenesses necessitate rigorous ethical standards in maintaining integrity while respecting artists’ creations.
In a market inviting impersonation through sophisticated clones, boundaries blurring ownership raise concerns surrounding artistic protection and intellectual property rights. Engaging transparent frameworks ensures systems honor consent when leveraging vocal outputs while educating users on establishing respectful norms within creative domains.
Misinformation and Authenticity
As text-to-speech technology’s client base burgeons, so too do risks surrounding misinformation dissemination and manipulation. Instances involving artificial speech creating falsified events or character impersonations lead to widening chasms of doubt cast through disinformation architecture infiltrating global dialogues. The manifestation of deepfake technology through TTS highlights complexities shaping narratives misleading communities away from core truths.
For creators and organizations invested in embracing innovation, preventing misuse assumes critical importance. Constructive partnerships between stakeholders and lawmakers breed sensible policies governing deployments. Fostering literacy surrounding information sources balances innovation with accountability, empowering users to decypher authenticity within meritocratic systems.
Societal Adjustments and Emotional Engagement Dynamics
Naturally occurring consequences emerge due to widespread incorporation of text-to-speech technology; social norms shape feelings elicited through reactionary tendencies that remain mediated through synthetic voices. Interactions transacting across personalized landscapes reveal dynamism shaping relationships while showcasing adjustments to emotional spectrums derived from auditory encounters.
As synthetic communication evolves prominently within interactions, considerable attention shifts towards nurturing authentic connections. Unpredicted adaptation challenges illustrate behavioral shifts toward deeper engagements rooted in rhetoric and mindful expression—leading to realms previously unattainable, enabling consciousness to flow effortlessly across synaptic waves.
User interfaces bridging complex networks present opportunities for rethinking conversation-culture modalities; as synthetics move past rote deliverables, they invoke multimedia reflexivity cultivated through intentional standpoint representation. These ramifications permit new empathetic experiential paths worth probing, provoking emergent discourse illuminating pathways historically neglected yet now recognized.
Conclusion
The journey of natural sounding text-to-speech reflects a transformational expedition destined to redefine interpersonal interaction while placing a diamond-studded lens on the volume of possibilities awaiting exploration. As we navigate through intelligent ecosystems bounded by creativity, emotional touchpoints amplify the richness of expressed communication—revealing the tapestries woven together by societal practices and technology together.
With each advancement, fresh revelations materialize beyond basic parameters of utility, illustrating the innate synergy fostered by marrying artificial intelligence and perceptible qualities embedded within human conversation. The urgent necessity for grounding ethics throughout development underscores the significance of conscientious methodologies driving designs fit for responsible pursuit—one that embodies authenticity, resourcefulness, and respect.
As we grasp the unfolding trajectories depicting natural sounding text-to-speech, a generalized aspiration thrives: to bridge potential divides fostering empathic connections while honoring disparate experiences and diversities threaded intricately through our cultural fabric. In whatever form, the spoken word rivers onward, decisively shaping testimonies enriching existence—setting the stage for dialogues that simply stir humanity forward.
0 responses to “Natural Sounding Text to Voice: Transform Your Writing into Life-Like Audio Effortlessly!”